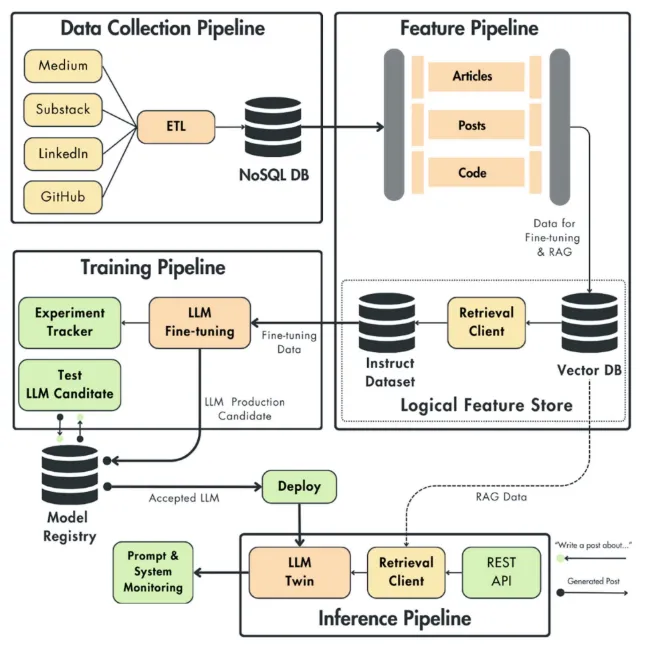
Featured Portfolio
- All
- GenAI&NLP
- ComputerVision
- TimeSeriesAnalysis
- FraudDetection

Satellite Image Segmentation
Process satellite images quickly and efficiently to generate segmented outputs in real time.
HealthVault.ai
Eva processes medical reports, scans, and videos, providing real-time, easy-to-understand insights.
Revenue and Product Demand Forecast System
End-to-end

MediSense-AI
Semantic Search Engine
FraudHawk
Anomaly detection in financial transactions via autoencoders and isolation forest.

Phishnet
LLM based Phishing mails catcher